The breadth of online collaborative tools that are emerging today is quite simply staggering! A number of websites have appeared offering specific product offerings, or hosting a multitude of collaborative tools (wiki's, blogs, forums, repositories, communication tools etc.) from which to work. What is so promising is the versatility and sophistication of products such as Thinkfold and Mindmeister, with niche products serving every kind of need imaginable. Crucially, many of these tools now offer real-time co-editing of documents (changes appear in real-time for all users), multiple user capability, rich timeline of changes and additional communication tools etc.
In the near future, we will likely see some consolidation and more compatibility amongst these products, as well as platforms which (on the fly) integrate tools into a single collaborative online environment from which to work.
In the meantime, Robin good , a social media guru, has put together a continually updated mindmap of online collaborative tools currently available at; http://www.mindmeister.com/maps/show_public/12213323 . The map offers an impressive list broken down by category of sites offering collaborative tools. They really are worth checking out!!
Copyright © 2006-2008 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.

Tuesday, May 26, 2009
Monday, May 25, 2009
Searching on the web; the new breed of search engines
There has been alot of talk recently (on the web and elsewhere) about the next generation of "smarter" search engines. Below are examples of search engines which have recently gained coverage over their ability to either (1) structure and present data pulled from the web, (2) assign semantic filtering by quality, (3) search structured data on the web, (4) search the 'real-time' web or (5) search the 'deep web':
(1) Structure and present data pulled from the web
Wolfram Alpha
'We aim to collect and curate all objective data; implement every known model, method, and algorithm; and make it possible to compute whatever can be computed about anything. Our goal is to build on the achievements of science and other systematizations of knowledge to provide a single source that can be relied on by everyone for definitive answers to factual queries.' (Wolfram, 2009) http://www.wolframalpha.com/
Google Squared
'Google Squared doesn't find webpages about your topic — instead, it automatically fetches and organizes facts from across the Internet.' (Google, 2009) It extracts data from relevant webpages and presents them in squared frames on a results page.
http://squared.google.com/
Bing
Bing is built to 'go beyond today's search experience' through recognising content and adapting to your query types, providing results which are "decision driven". According to the company; "we set out to create a new type of search experience with improvements in three key areas: (1) Delivering great search results and one-click access to relevant information, (2) Creating a more organized search experience, (3) Simplifying tasks and providing tools that enable insight about key decisions." (Microsoft, 2009)
http://www.bing.com/
http://www.discoverbing.com/
Sensebot
'SenseBot delivers a summary in response to your search query instead of a collection of links to Web pages. SenseBot parses results from the Web and prepares a text summary of them. The summary serves as a digest on the topic of your query, blending together the most significant and relevant aspects of the search results. The summary itself becomes the main result of your search...Sensebot attempts to understand what the result pages are about. It uses text mining to parse Web pages and identify their key semantic concepts. It then performs multidocument summarization of content to produce a coherent summary' (Sensebot, 2008)
http://www.sensebot.net/
(2) Provide more semantic filtering of information by quality
Hakia
'Hakia’s semantic technology provides a new search experience that is focused on quality, not popularity. hakia’s quality search results satisfy three criteria simultaneously: They (1) come from credible Web sites recommended by librarians, (2) represent the most recent information available, and (3) remain absolutely relevant to the query' (Hakia, 2009)
http://www.hakia.com/
(3) Search structured data on the web
SWSE
' There is already a lot of data out there which conforms to the proposed SW standards (e.g. RDF and OWL). Small vertical vocabularies and ontologies have emerged, and the community of people using these is growing daily. People publish descriptions about themselves using FOAF (Friend of a Friend), news providers publish newsfeeds in RSS (RDF Site Summary), and pictures are being annotated using various RDF vocabularies. [SWSE is] service which continuously explores and indexes the Semantic Web and provides an easy-to-use interface through which users can find the data they are looking for. We are therefore developing a Semantic Web Search Engine' (SWSE, 2009)
http://swse.deri.org/
Swoogle
'Swoogle is a search engine for the Semantic Web on the Web. Swoogle crawl the World Wide Web for a special class of web documents called Semantic Web documents, which are written in RDF' (Swoogle, 2007)
http://swoogle.umbc.edu/
Similar offering is;
http://watson.kmi.open.ac.uk/WatsonWUI/
(4) Search the 'real-time' web
One Riot
'OneRiot crawls the links people share on Twitter, Digg and other social sharing services, then indexes the content on those pages in seconds. The end result is a search experience that allows users to find the freshest, most socially-relevant content from across the realtime web....we index our search results according to their current relevance and popularity' (Oneriot, 2009)
http://www.oneriot.com/
Scoopler
'Scoopler is a real-time search engine. We aggregate and organize content being shared on the internet as it happens, like eye-witness reports of breaking news, photos and videos from big events, and links to the hottest memes of the day. We do this by constantly indexing live updates from services including Twitter, Flickr, Digg, Delicious and more.' (Scoopler, 2009)
http://www.scoopler.com/
Collecta
'Collecta monitors the update streams of news sites, popular blogs and social media, and Flickr, so we can show you results as they happen' (Collecta. 2009).
http://www.collecta.com/
(5) Search the 'deep web'
DeepDyve
'The DeepDyve research engine uses proprietary search and indexing technology to cull rich, relevant content from thousands of journals, millions of documents, and billions of untapped Deep Web pages.' 'Researchers, students, technical professionals, business users, and other information consumers can access a wealth of untapped information that resides on the "Deep Web" – the vast majority of the Internet that is not indexed by traditional, consumer-based search engines. The DeepDyve research engine unlocks this in-depth, professional content and returns results that are not cluttered by opinion sites and irrelevant content.... The KeyPhrase™ algorithm, applies indexing techniques from the field of genomics. The algorithm matches patterns and symbols on a scale that traditional search engines cannot match, and it is perfectly suited for complex data found on the Deep Web' (Deepdyve, 2009)
http://www.deepdyve.com/
Copyright © 2006-2008 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
(1) Structure and present data pulled from the web
Wolfram Alpha
'We aim to collect and curate all objective data; implement every known model, method, and algorithm; and make it possible to compute whatever can be computed about anything. Our goal is to build on the achievements of science and other systematizations of knowledge to provide a single source that can be relied on by everyone for definitive answers to factual queries.' (Wolfram, 2009) http://www.wolframalpha.com/
Google Squared
'Google Squared doesn't find webpages about your topic — instead, it automatically fetches and organizes facts from across the Internet.' (Google, 2009) It extracts data from relevant webpages and presents them in squared frames on a results page.
http://squared.google.com/
Bing
Bing is built to 'go beyond today's search experience' through recognising content and adapting to your query types, providing results which are "decision driven". According to the company; "we set out to create a new type of search experience with improvements in three key areas: (1) Delivering great search results and one-click access to relevant information, (2) Creating a more organized search experience, (3) Simplifying tasks and providing tools that enable insight about key decisions." (Microsoft, 2009)
http://www.bing.com/
http://www.discoverbing.com/
Sensebot
'SenseBot delivers a summary in response to your search query instead of a collection of links to Web pages. SenseBot parses results from the Web and prepares a text summary of them. The summary serves as a digest on the topic of your query, blending together the most significant and relevant aspects of the search results. The summary itself becomes the main result of your search...Sensebot attempts to understand what the result pages are about. It uses text mining to parse Web pages and identify their key semantic concepts. It then performs multidocument summarization of content to produce a coherent summary' (Sensebot, 2008)
http://www.sensebot.net/
(2) Provide more semantic filtering of information by quality
Hakia
'Hakia’s semantic technology provides a new search experience that is focused on quality, not popularity. hakia’s quality search results satisfy three criteria simultaneously: They (1) come from credible Web sites recommended by librarians, (2) represent the most recent information available, and (3) remain absolutely relevant to the query' (Hakia, 2009)
http://www.hakia.com/
(3) Search structured data on the web
SWSE
' There is already a lot of data out there which conforms to the proposed SW standards (e.g. RDF and OWL). Small vertical vocabularies and ontologies have emerged, and the community of people using these is growing daily. People publish descriptions about themselves using FOAF (Friend of a Friend), news providers publish newsfeeds in RSS (RDF Site Summary), and pictures are being annotated using various RDF vocabularies. [SWSE is] service which continuously explores and indexes the Semantic Web and provides an easy-to-use interface through which users can find the data they are looking for. We are therefore developing a Semantic Web Search Engine' (SWSE, 2009)
http://swse.deri.org/
Swoogle
'Swoogle is a search engine for the Semantic Web on the Web. Swoogle crawl the World Wide Web for a special class of web documents called Semantic Web documents, which are written in RDF' (Swoogle, 2007)
http://swoogle.umbc.edu/
Similar offering is;
http://watson.kmi.open.ac.uk/WatsonWUI/
(4) Search the 'real-time' web
One Riot
'OneRiot crawls the links people share on Twitter, Digg and other social sharing services, then indexes the content on those pages in seconds. The end result is a search experience that allows users to find the freshest, most socially-relevant content from across the realtime web....we index our search results according to their current relevance and popularity' (Oneriot, 2009)
http://www.oneriot.com/
Scoopler
'Scoopler is a real-time search engine. We aggregate and organize content being shared on the internet as it happens, like eye-witness reports of breaking news, photos and videos from big events, and links to the hottest memes of the day. We do this by constantly indexing live updates from services including Twitter, Flickr, Digg, Delicious and more.' (Scoopler, 2009)
http://www.scoopler.com/
Collecta
'Collecta monitors the update streams of news sites, popular blogs and social media, and Flickr, so we can show you results as they happen' (Collecta. 2009).
http://www.collecta.com/
(5) Search the 'deep web'
DeepDyve
'The DeepDyve research engine uses proprietary search and indexing technology to cull rich, relevant content from thousands of journals, millions of documents, and billions of untapped Deep Web pages.' 'Researchers, students, technical professionals, business users, and other information consumers can access a wealth of untapped information that resides on the "Deep Web" – the vast majority of the Internet that is not indexed by traditional, consumer-based search engines. The DeepDyve research engine unlocks this in-depth, professional content and returns results that are not cluttered by opinion sites and irrelevant content.... The KeyPhrase™ algorithm, applies indexing techniques from the field of genomics. The algorithm matches patterns and symbols on a scale that traditional search engines cannot match, and it is perfectly suited for complex data found on the Deep Web' (Deepdyve, 2009)
http://www.deepdyve.com/
Copyright © 2006-2008 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
Monday, May 18, 2009
How to personalise images for illuminous desktop wallpaper
Here is my 'how to' for personalising the winning shot of the 'International Garden photo' competition over at Igpoty . The results should make some illuminous desktop wallpaper for your computer.
1. Open the following image (available at Igpoty ) in Photoshop :

2. Use the lasso tool to mark out and highlight the sky (3 pieces). You'll need to copy each piece separately, then paste to a new layer
3. When all layers are copied. Merge them them until you have 1 piece.
4. Next use the lasso tool to mark out and copy the girl. Paste to a new layer. Do the same for the rock.
5. You should now have 3 additional layers on top of the original. If you hide the original layer, you should see the following;
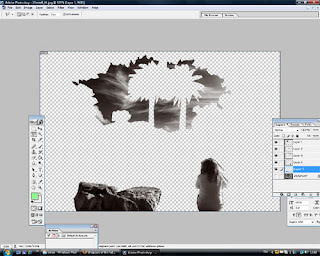

 8. Finally, if you like, you can add additional effects such as rendering a 'Lens flare':
8. Finally, if you like, you can add additional effects such as rendering a 'Lens flare':

9. You may want to enlarge the original image to the resolution of your desktop before saving.
10. Choose 'save for web' and save as a Jpeg image.
11. And thats it, you should have a terrific personalised desktop wallpaper or screensaver.
Here is a link to download 1200x1800 resolution images of the examples above;
http://rapidshare.com/files/234404204/screensavers.zip.html
Copyright © 2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
1. Open the following image (available at Igpoty ) in Photoshop :

2. Use the lasso tool to mark out and highlight the sky (3 pieces). You'll need to copy each piece separately, then paste to a new layer
3. When all layers are copied. Merge them them until you have 1 piece.
4. Next use the lasso tool to mark out and copy the girl. Paste to a new layer. Do the same for the rock.
5. You should now have 3 additional layers on top of the original. If you hide the original layer, you should see the following;

6. You can now very lightly feather these new layers (1px or 2px max) so that they will eventually blend better with the original layer.
7. Use the 'Gradient Map' in 'Adjustments' to create a gradient of colours for both the original layer and the 'sky' layer. Below are example's of the finished product:



9. You may want to enlarge the original image to the resolution of your desktop before saving.
10. Choose 'save for web' and save as a Jpeg image.
11. And thats it, you should have a terrific personalised desktop wallpaper or screensaver.
Here is a link to download 1200x1800 resolution images of the examples above;
http://rapidshare.com/files/234404204/screensavers.zip.html
Copyright © 2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
Sunday, March 22, 2009

Friday, March 13, 2009
Twitter and it's data free for all....
The rise of Twitter
Twitter is expanding and expanding fast. A flurry of news coverage and hype about the product, particularly in the last 3 months, has seen users flock to the service. Twitter is seen to offer enormous potential, information can be filtered by content, location, keyword etc., opening up the realms of how data is used online in real time. This is in tandem with the numerous benefits of openness discussed below. However, Twitter still has some way to go. It has yet to come to terms with its own potential and how those possibilities should be steered and constrained. The service recently made some small developments to its site, with a 'trend' and 'search' facility added. However, the sophistication of its privacy and account settings is still limited. Thus, it has yet to put more control back in users hand, with regard to how their data is used and by whom. At present, it is an all or nothing affair, you're "open" or you're "private"!!. This begs the following questions, should account holders have more control over their data? If so, why should this be the case? Is openness itself constraining what people will say? Finally, If users have more control, will this stifle the success of the service?
Why openness?
The Twitter model is built largely around individuals posting short 140 character status updates, replies or retweets on any range of topic imaginable. Individuals can find and follow any other user on the service, ranging from friends to common interests, to celebrities etc. The great thing about twitter is its 'openness'. Most individuals choose to keep their profile public to ensure that they can be found by like-minded individuals, or that ongoing conversations can be picked up by interested parties etc. It means individuals have that feeling that someone out there is listening, even if it is just the possibility of feeling part of something. It is a forum for expression of the mind, even if expression is mundane. It is also a means to 'contribute' one's time, knowledge and experience and is thus an avenue of 'meaning' for individuals.
Openness ensures that those with something to offer others can more easily be heard. It engenders the possibility for more connection, collaboration, relationship and even community formation 'without' boundaries. By focusing on the content of messages and less on the full personality, it provides a different kind of social formation. The loud, influential and dominant personality may not make for interesting dialogue. Too many annoying tweets from a user and one can easily unfollow with the click of the mouse. This levels the playing field for users in many respects, as well as increasing the possibility of connection based on interest and not by persuasion. However, not everyone wishes for this openness. There is the option to set your profile 'private' in order to close your information to only those with whom you've allowed follow you.
Interpreting your past online
Full openness has its price though, Twitter first launched in March 2006, and since then, an archive of user data has slowly being amounting for all to access. Hundreds of your messages may (or may not) be carefully vetted by you, but one thoughtless twitter update may be enough to get you in to trouble at any point in the future. This may be nothing more than friends misinterpreting and taking offence to an update. But it could be something more: Recently a US cop had his status updates on Facebook and Myspace used as evidence against him in a gun trial on grounds of the accused acquittal. What was interesting about this case is how status updates became utilised and crucially 'interpreted' by the Jury. This highlights how information may be interpreted and placed into multiple contexts by whoever reads the information. Employers, even potential collaborators, may selectively choose just one suspect twitter update among hundreds as 'proof' of character, or misintrepret one's online ego as holistically representative of the individual. Twitter means your online past and identity will always be there online, waiting to be interpreted and analysed.
Analyse this!
You may think that with hundreds of recorded messages, it would be uncumbersome for anyone to want to thrall through your past data. But with twitter, software by third parties is springing up to offer just that: Twitter analyzer is just one of the free online applications available that allows you to analyse the data of "any" twitter user with an open account (hence the majority of twitter user). The bounds of what can be achieved with Twitter analyzer is limited. But it opens numerous possibilities. For beyond harmless apps like Twitscoop, which scrape status updates in order to form twitter 'trending topics' and 'buzz words', your data can be analysed in isolation or in tandem with others, in any number of ways, for any number of purposes, and by ANYONE. Twitter apps may emerge (if they don't already exist) to 'profile' individuals; to elucidate personality, truth and inconsistency, track record, literacy, interests etc. etc. etc. This is alongside the likely emergence of targeted advertising etc, and data mining of information, in order to make twitter a viable business model.
Openness on whose terms?
At present twitter has a very lax attitude to its data. If you have your profile public, your data is a free for all. If it's private, its between you, your vetted followers and twitter. This means that Twitter's so called openness may not be so open. People are constantly vetting and reflecting on what information they post on twitter. They may do it out of shyness, cautiousness, personal branding, or foresight etc. Twitter is open for many, but not too open. It's very openness curtails what dialogue does occur online. As users become aware of the ways in which their data can be used, this may further curtail individual expression. Thus, should Twitter not increase the range of choices with regard 'openness' and 'privacy'. What I would like to see is the possibility of users having the choice to make private their archive of data. For instance, what if only your recent updates were set as public? What if twitter made it difficult for those updates to be scraped by third party offerings? What if you could make replies only visible to who you follow? What if you could automatically make messages with certain 'keywords' private? What if you could make certain messages time sensitive and private after a certain period? What if you could make some status updates private to yourself? Thus, the bounds of privacy can be opened up. Will it constrain the services success however? I do not believe so, if too much openness is stifling expression and conversation on twitter, than increasing the scope of openness versus privacy, and doing it in an uncumbersome way; would perhaps increase use of the service. This choice may be the business model Twitter hopes for...
Copyright © 2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
Twitter is expanding and expanding fast. A flurry of news coverage and hype about the product, particularly in the last 3 months, has seen users flock to the service. Twitter is seen to offer enormous potential, information can be filtered by content, location, keyword etc., opening up the realms of how data is used online in real time. This is in tandem with the numerous benefits of openness discussed below. However, Twitter still has some way to go. It has yet to come to terms with its own potential and how those possibilities should be steered and constrained. The service recently made some small developments to its site, with a 'trend' and 'search' facility added. However, the sophistication of its privacy and account settings is still limited. Thus, it has yet to put more control back in users hand, with regard to how their data is used and by whom. At present, it is an all or nothing affair, you're "open" or you're "private"!!. This begs the following questions, should account holders have more control over their data? If so, why should this be the case? Is openness itself constraining what people will say? Finally, If users have more control, will this stifle the success of the service?
Why openness?
The Twitter model is built largely around individuals posting short 140 character status updates, replies or retweets on any range of topic imaginable. Individuals can find and follow any other user on the service, ranging from friends to common interests, to celebrities etc. The great thing about twitter is its 'openness'. Most individuals choose to keep their profile public to ensure that they can be found by like-minded individuals, or that ongoing conversations can be picked up by interested parties etc. It means individuals have that feeling that someone out there is listening, even if it is just the possibility of feeling part of something. It is a forum for expression of the mind, even if expression is mundane. It is also a means to 'contribute' one's time, knowledge and experience and is thus an avenue of 'meaning' for individuals.
Openness ensures that those with something to offer others can more easily be heard. It engenders the possibility for more connection, collaboration, relationship and even community formation 'without' boundaries. By focusing on the content of messages and less on the full personality, it provides a different kind of social formation. The loud, influential and dominant personality may not make for interesting dialogue. Too many annoying tweets from a user and one can easily unfollow with the click of the mouse. This levels the playing field for users in many respects, as well as increasing the possibility of connection based on interest and not by persuasion. However, not everyone wishes for this openness. There is the option to set your profile 'private' in order to close your information to only those with whom you've allowed follow you.
Interpreting your past online
Full openness has its price though, Twitter first launched in March 2006, and since then, an archive of user data has slowly being amounting for all to access. Hundreds of your messages may (or may not) be carefully vetted by you, but one thoughtless twitter update may be enough to get you in to trouble at any point in the future. This may be nothing more than friends misinterpreting and taking offence to an update. But it could be something more: Recently a US cop had his status updates on Facebook and Myspace used as evidence against him in a gun trial on grounds of the accused acquittal. What was interesting about this case is how status updates became utilised and crucially 'interpreted' by the Jury. This highlights how information may be interpreted and placed into multiple contexts by whoever reads the information. Employers, even potential collaborators, may selectively choose just one suspect twitter update among hundreds as 'proof' of character, or misintrepret one's online ego as holistically representative of the individual. Twitter means your online past and identity will always be there online, waiting to be interpreted and analysed.
Analyse this!
You may think that with hundreds of recorded messages, it would be uncumbersome for anyone to want to thrall through your past data. But with twitter, software by third parties is springing up to offer just that: Twitter analyzer is just one of the free online applications available that allows you to analyse the data of "any" twitter user with an open account (hence the majority of twitter user). The bounds of what can be achieved with Twitter analyzer is limited. But it opens numerous possibilities. For beyond harmless apps like Twitscoop, which scrape status updates in order to form twitter 'trending topics' and 'buzz words', your data can be analysed in isolation or in tandem with others, in any number of ways, for any number of purposes, and by ANYONE. Twitter apps may emerge (if they don't already exist) to 'profile' individuals; to elucidate personality, truth and inconsistency, track record, literacy, interests etc. etc. etc. This is alongside the likely emergence of targeted advertising etc, and data mining of information, in order to make twitter a viable business model.
Openness on whose terms?
At present twitter has a very lax attitude to its data. If you have your profile public, your data is a free for all. If it's private, its between you, your vetted followers and twitter. This means that Twitter's so called openness may not be so open. People are constantly vetting and reflecting on what information they post on twitter. They may do it out of shyness, cautiousness, personal branding, or foresight etc. Twitter is open for many, but not too open. It's very openness curtails what dialogue does occur online. As users become aware of the ways in which their data can be used, this may further curtail individual expression. Thus, should Twitter not increase the range of choices with regard 'openness' and 'privacy'. What I would like to see is the possibility of users having the choice to make private their archive of data. For instance, what if only your recent updates were set as public? What if twitter made it difficult for those updates to be scraped by third party offerings? What if you could make replies only visible to who you follow? What if you could automatically make messages with certain 'keywords' private? What if you could make certain messages time sensitive and private after a certain period? What if you could make some status updates private to yourself? Thus, the bounds of privacy can be opened up. Will it constrain the services success however? I do not believe so, if too much openness is stifling expression and conversation on twitter, than increasing the scope of openness versus privacy, and doing it in an uncumbersome way; would perhaps increase use of the service. This choice may be the business model Twitter hopes for...
Copyright © 2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
Monday, February 16, 2009
It's my data not yours!
Like many of you, I've been using 'web 2.0' sites for some time now. My use of them seems to be increasing and expanding of late. They allow someone like myself, who spends alot of time stuck in front of a computer, to maintain some degree of social interaction, express my interests and thus hold my sanity at bay.
In fact, I've come to like these new online offerings so much, that I want to do more!! For instance, I've been playing around with the idea of keeping an online journal for some time now. Having chosen a service that I liked; 'Penzu' , I realised that after keeping entries for more than a week, I had no assurance as to the integrity and access to data in the event of this service ceasing. The site gave no assurance about data portability or policy with regard to cessation of service. Then, I came across this interesting article by Bill Thompson over at the BBC See article: http://news.bbc.co.uk/2/hi/technology/7760528.stm
He rightly raised the issue of data portability concluding that web site developers should do more. (Data Portability concerns the ability for user data to be transferred to another service, or downloaded by the user.) However I think he failed to fully argue what should be done about this issue. For example, if your data and/or intellectual property resides on a free online site, and that service changes its offering; is it made transparent and simple if you decide to jump ship to another offering? If your data and/or intellectual property resides on an online website and that website goes bust, will your data be kept safe and retrievable?
We already have some national government policies in place concerning the protection, control and privacy of data to individuals. However, I feel it should also be up to government to protect citizens with regard to movement, ownership and integrity of user data. For instance, more needs to be done to ensure that website owners have a required responsibility from the outset; to provide data portability and maintain this ability even after termination of service. Perhaps, this would require that the government step in and provide servers to back up user data in the event of a company ceasing. This could be in tandem with services (new or old) being required to ensure data integrity in the case of termination of service etc. Issues like ownership of data also needs to be addressed.
It is often argued that government should not inhibit the market, but I argue that the government should steer the market, maximising the longterm interests of it's citizens. Thus, I don't see a problem with positive interference in the market. The role of government is afterall to balance the realms of life. This is in view of citizens becoming increasingly reliant on the market, and thus, on online commercial offerings to function and stay abreast of modern society. Of course the supra national nature of the web, will require the need for supranational cooperation on any kind of intervention. Political intervention may quicken the pace of progress on these issues, it could also ensure that data rights and opt-out facilities are apparent and transparent to citizens. Finally, certain government measures may benefit both users and service offerings in the long term, by instilling confidence. For instance, a service like Penzu would perhaps better thrive if minimum requirements were in place, granted the details of any technical standards is a messy and arduous business. This kind of confidence, that individuals have certain assurances; would in aggregate serve to speed up adoption of existing and emerging services. It would also assure vigilance, in the face of further encroachment of the market into everyday life.
Copyright © 2006-2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
See; Facebook retain right to user data after account deletion
In fact, I've come to like these new online offerings so much, that I want to do more!! For instance, I've been playing around with the idea of keeping an online journal for some time now. Having chosen a service that I liked; 'Penzu' , I realised that after keeping entries for more than a week, I had no assurance as to the integrity and access to data in the event of this service ceasing. The site gave no assurance about data portability or policy with regard to cessation of service. Then, I came across this interesting article by Bill Thompson over at the BBC See article: http://news.bbc.co.uk/2/hi/technology/7760528.stm
He rightly raised the issue of data portability concluding that web site developers should do more. (Data Portability concerns the ability for user data to be transferred to another service, or downloaded by the user.) However I think he failed to fully argue what should be done about this issue. For example, if your data and/or intellectual property resides on a free online site, and that service changes its offering; is it made transparent and simple if you decide to jump ship to another offering? If your data and/or intellectual property resides on an online website and that website goes bust, will your data be kept safe and retrievable?
We already have some national government policies in place concerning the protection, control and privacy of data to individuals. However, I feel it should also be up to government to protect citizens with regard to movement, ownership and integrity of user data. For instance, more needs to be done to ensure that website owners have a required responsibility from the outset; to provide data portability and maintain this ability even after termination of service. Perhaps, this would require that the government step in and provide servers to back up user data in the event of a company ceasing. This could be in tandem with services (new or old) being required to ensure data integrity in the case of termination of service etc. Issues like ownership of data also needs to be addressed.
It is often argued that government should not inhibit the market, but I argue that the government should steer the market, maximising the longterm interests of it's citizens. Thus, I don't see a problem with positive interference in the market. The role of government is afterall to balance the realms of life. This is in view of citizens becoming increasingly reliant on the market, and thus, on online commercial offerings to function and stay abreast of modern society. Of course the supra national nature of the web, will require the need for supranational cooperation on any kind of intervention. Political intervention may quicken the pace of progress on these issues, it could also ensure that data rights and opt-out facilities are apparent and transparent to citizens. Finally, certain government measures may benefit both users and service offerings in the long term, by instilling confidence. For instance, a service like Penzu would perhaps better thrive if minimum requirements were in place, granted the details of any technical standards is a messy and arduous business. This kind of confidence, that individuals have certain assurances; would in aggregate serve to speed up adoption of existing and emerging services. It would also assure vigilance, in the face of further encroachment of the market into everyday life.
Copyright © 2006-2009 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
See; Facebook retain right to user data after account deletion
Tuesday, January 20, 2009
Response to; I haz a Nom
A friend of mine; 'Victoria MacArthur' over at 'Propositional Structure' , today wrote an interesting muse about personal writings on blogs. In it, she put forward the question; as to how personal one should get in a blog? How much does one 'feel comfortable' with sharing on the web? And, what are the ramifications in terms of employers vetting candidates for jobs etc. ?
She seemed to raise 2 fundamental issues:
1. The question of instinctually or more cognitively wanting to protect and control one's identity.
2. The pragmatic issues around needing to negotiate one's privacy on the web.
This got me thinking about some of the key issues at stake which I've layed out as follows:
First off, there is the problem of ‘identity crime’. This is a type of crime which is on the increase and one further enabled by the web. This can occur whereby you leave enough breadcrumbs on the internet for someone to cross-correlate that information and build up a profile on you. This profile can then be used to create a false identity for another person, or even worse; to 'steal' someones identity. Outside of crime though, it may be a case that you unknowingly have left the jig-saw for an online profile of you, which can be pieced together by employers and others. Thus, you may incremently and unknowingly lose your privacy online.
Second off, identity in the 21st century has increasingly become ‘individuated’, whereby individuals construct the ’self’ through-out their lives. (Note: This construction can be conscious, unconconscious and indeed shaped with social structure at micro, meso, macro level) What’s important about posting information on the internet, is that it can leave relics of your previous ’selves’. Thus, your past can constrain your identity ‘construction’, particularly when it cannot be erased from the past. For example, archive.org has been archiving web pages on the internet for nearly 10 years now. Fragments of your past identities on the internet can be seen as both positive and negative. One positive, is that it means you have to face all of your past realities (and integrate them). On a negative, it can give people (such as employers) a false sense of who you are ‘now’; your past may constrain you in the eyes of others. It may also constrain your own sense of identity and your ability to construct.
Third Point. There is an issue with social networking sites etc., whereby individuals can have too much ‘control’ of their online identities. Individuals can now put themselves in a position to be able to package their life online, and this online construction may not be ‘holistically’ representative of the integrated identity. It may represent a planned and controlled fragment of your identity, or even an entirely consciously manufactured identity. At the other extreme, the fragments of identity that do lie on the internet, may result in people constructing a narrow and perhaps even false sense of who you are as an integrated identity.
Final point. The solution to all this seems 3 fold. (1)Government policy with regards to data protection etc. (2)Some responsibility and forsight with regard to website owners and content managers (3)Individual responsiblity, in terms of managing your online identity and maintaining a degree of foresight.
Overall, it seems like there isn’t a polarising solution. A balanced attitude to your identity and privacy on the internet seems the best approach. Individuals need to be vigilant and maintain foresight when posting information on the web. On the other-hand, individuals need to be attentive to how, ‘controlled’ and ‘representative’ that information on the web is of their ‘integrated identity’.
To see the original article, go to; http://www.victoriamacarthur.com/2009/01/20/i-haz-a-nom/
Copyright © 2006-2008 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
She seemed to raise 2 fundamental issues:
1. The question of instinctually or more cognitively wanting to protect and control one's identity.
2. The pragmatic issues around needing to negotiate one's privacy on the web.
This got me thinking about some of the key issues at stake which I've layed out as follows:
First off, there is the problem of ‘identity crime’. This is a type of crime which is on the increase and one further enabled by the web. This can occur whereby you leave enough breadcrumbs on the internet for someone to cross-correlate that information and build up a profile on you. This profile can then be used to create a false identity for another person, or even worse; to 'steal' someones identity. Outside of crime though, it may be a case that you unknowingly have left the jig-saw for an online profile of you, which can be pieced together by employers and others. Thus, you may incremently and unknowingly lose your privacy online.
Second off, identity in the 21st century has increasingly become ‘individuated’, whereby individuals construct the ’self’ through-out their lives. (Note: This construction can be conscious, unconconscious and indeed shaped with social structure at micro, meso, macro level) What’s important about posting information on the internet, is that it can leave relics of your previous ’selves’. Thus, your past can constrain your identity ‘construction’, particularly when it cannot be erased from the past. For example, archive.org has been archiving web pages on the internet for nearly 10 years now. Fragments of your past identities on the internet can be seen as both positive and negative. One positive, is that it means you have to face all of your past realities (and integrate them). On a negative, it can give people (such as employers) a false sense of who you are ‘now’; your past may constrain you in the eyes of others. It may also constrain your own sense of identity and your ability to construct.
Third Point. There is an issue with social networking sites etc., whereby individuals can have too much ‘control’ of their online identities. Individuals can now put themselves in a position to be able to package their life online, and this online construction may not be ‘holistically’ representative of the integrated identity. It may represent a planned and controlled fragment of your identity, or even an entirely consciously manufactured identity. At the other extreme, the fragments of identity that do lie on the internet, may result in people constructing a narrow and perhaps even false sense of who you are as an integrated identity.
Final point. The solution to all this seems 3 fold. (1)Government policy with regards to data protection etc. (2)Some responsibility and forsight with regard to website owners and content managers (3)Individual responsiblity, in terms of managing your online identity and maintaining a degree of foresight.
Overall, it seems like there isn’t a polarising solution. A balanced attitude to your identity and privacy on the internet seems the best approach. Individuals need to be vigilant and maintain foresight when posting information on the web. On the other-hand, individuals need to be attentive to how, ‘controlled’ and ‘representative’ that information on the web is of their ‘integrated identity’.
To see the original article, go to; http://www.victoriamacarthur.com/2009/01/20/i-haz-a-nom/
Copyright © 2006-2008 Shane McLoughlin. This article may not be resold or redistributed without prior written permission.
Subscribe to:
Posts (Atom)

